NUMBER OF SENTENCES FOUND: 99
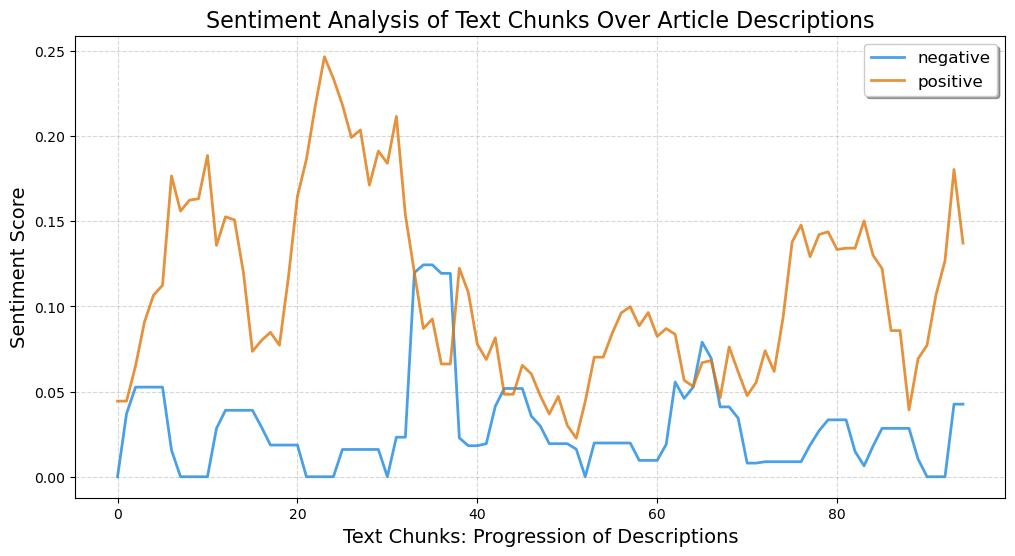
TOTAL AVERAGE SENTIMENT: [0.10641414 0.02876768 0.86480808 0.3293798 ]
VOCAB LENGTH 1089
[['ahead', 'sixthgeneration', 'honda', 'crvs', 'malaysian', 'launch', 'expected', 'later', 'month', 'honda', 'malaysia', 'ha', 'previewing', 'suv', 'via', 'series', 'customer', 'showcase', 'selected', 'dealership', 'across', 'country'], ['preview', 'post', '2024', 'honda', 'cr', 'bn'], ['frank', 'recently', 'reported', 'electric', 'vehicle', 'ev', 'sale', 'way', 'u', 'vehicle', 'continue', 'city', 'unveils', 'section', 'road', 'allows', 'ev', 'driver', 'wirelessly', 'charge', 'vehicle', 'drive', 'lcnb', 'corp', 'decreased', 'holding', 'tesla', 'inc', 'nasdaq', 'tsla', 'free', 'report', '176', 'second', 'quarter', 'according', 'recent', 'filing', 'security', 'exchange', 'commission'], ['firm', 'owned', '4270', 'share', 'electric', 'vehicle', 'producer', 'stock', 'many', 'younger', 'buyer', 'opting', 'preowned', 'car', 'new', '45m', 'sold', 'india', 'last', 'year'], ['startup', 'usedcar', 'segment', 'focusing', 'techbased', 'solution', 'ancillary', 'service', 'unit', 'economics', 'tap', 'largely', 'unorganised', 'market']]